Java反序列化系列(1)——基础篇
Java反序列化系列(1)——基础篇
前言
自古云,九层之台,起于垒土。
这几年常见的漏洞皆是Java的问题,例如fastjson、shiro、log4j2等,比较热门的漏洞都和Java有关,说白了都和反序列化有关。目前比较前沿的技术、安全研究都集中在Java这里。
本系列旨在记录自己学习Java安全历程,参照了 Y4tacker 师傅的学习笔记及白日梦组长师傅的视频。
本文旨在重新梳理Java反序列化内容,打好基础知识,为后续Java安全做好铺垫。
序列化及反序列化概述
序列化与反序列化
Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指把字节序列恢复为Java对象的过程。
序列化:ObjectOutputStream类 –> writeObject()
该方法对参数指定的obj对象进行序列化,把字节写到一个目标输出流中,按Java的标准约定是给文件一个.ser扩展名。
反序列化:ObjectIntputStream类 –> readObject()
该方法从一个源输入流中读取字节序列,再把他们反序列化为一个对象,并将其返回。
- 一段数据以
rO0AB开头,基本可以确定这串是JAVA序列化后base64加密的数据 - 如果以
aced开头,那么他就是这一段java序列化的16进制。 - 常见的序列化和反序列化协议如:原生、xml&SOAP、JSON、Protobuf
于是,一个自然而然的问题就会 出现,我们为什么要使用序列化和反序列化呢?
当我们只在本地JVM里运行Java实例,这个时候通常不需要序列化和反序列化,但当我们需要将内存中的对象持久化到磁盘、数据库中时,或者需要与浏览器进行交互,这个时候就需要序列化了。
Java进程之间通信时,若在进程之间需要传递对象,会用到序列化和反序列化。
也即发送方需要把这个Java对象转换为字节序列,然后在网络上传送;接收方需要从字节序列中恢复出Java对象。
序列化的好处
(1) 能够实现数据的持久化,通过序列化可以把数据永久的保存在硬盘上,也可以理解为通过序列化将数据保存在文件中。
(2) 利用序列化实现远程通信,在网络上传送对象的字节序列。
常见的使用位置:
- 远程调用/进程间通信(有线协议、web services、不同系统/进程之间通信)
- 缓存/持久化(数据库、缓存服务器、文件系统、程序未来数据通信)
- Tokens (不同系统/进程之间通信数据,HTTP cookies,HTML 表单数据,API 认证 tokens)
序列化及反序列化代码实现
在IDEA中新建几个类
- Person.java
1 | |
- 序列化文件:SerializationTest.java
1 | |
- 反序列化文件:UnserializeTest.java
1 | |
运行一下序列化的代码
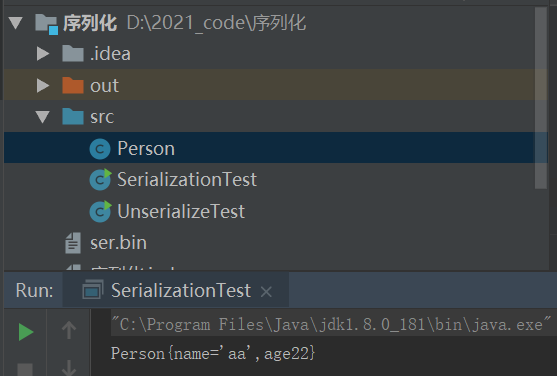
可以看到序列化成功并且通过这个FileOutputStream输出流对象,将序列化的对象输出到ser.bin当中。
这样我们就实现了Java原生的序列化功能。
再来运行一下反序列化的代码,通过反序列化成功读取到了ser.bin中的内容
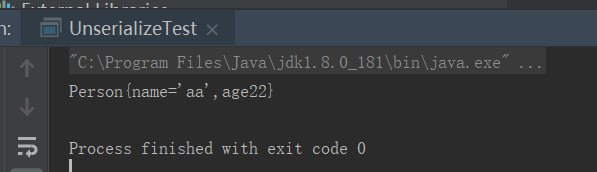
这里有什么要注意的点呢?
Person类如果没有实现了Serializable接口,序列化就会报错。只有实现 了Serializable或者 Externalizable接口的类的对象才能被序列化为字节序列。(不是则会抛出异常)
- 并且Serializable 接口是 Java 提供的序列化接口,它是一个空接口,所以其实我们不需要实现什么。
public interface Serializable { }
在反序列化过程中,它的父类如果没有实现序列化接口,那么将需要提供无参构造函数来重新创建对象。
一个实现 Serializable 接口的子类也是可以被序列化的。
静态成员变量是不能被序列化。序列化是针对对象属性的,而静态成员变量是属于类的。
transient 标识的对象成员变量不参与序列化
有些快递打包和拆包时有特殊的需求,比如易碎朝上。类比我们也可以重写readObject和writeObject方法,如果类中实现了这两个方法,在序列化和反序列化的过程中就不会调用系统自带的,而是我们重写的。
序列化及反序列化安全
序列化及反序列化为什么会产生安全问题呢?
只要服务端反序列化数据,客户端传递类的readObject中代码会自动执行,给予攻击者在服务器上运行代码的能力。
可能的形式:
入口类的readObject直接调用危险方法。
拿上文代码举例,比如Person中重写了
readObject方法1
2
3
4private void readObject(ObjectInputStream ois) throws IOException , ClassNotFoundException{
ois.defaultReadObject();
Runtime.getRuntime().exec("calc");
}将Person序列化,再进行反序列化,这时候就会弹出计算器窗口。
这样我们岂不是想实现什么就是实现什么了吗?颇有种一身转战三千里,一剑曾当百万师的快意!
然而这种情况基本上是不可能会出现的,这么危险的类不会这么写,就算有的话也是程序员自己写来测试东西,没有源码的情况下不会发现。
入口类参数中包含可控类,该类有危险方法,readObject时调用。
入口类参数中包含可控类,该类又调用其他危险方法的类,readObject时调用。
构造函数/静态代码块等类加载时隐式执行
产生漏洞的攻击路线
共同条件:继承Seriallizable
入口类:source(重写readObject 调用常见的函数 参数类型宽泛 最好jdk自带)
调用链:gadget chain 相同名称 相同类型
执行类:sink (rce ssrf写文件等)最重要
以 HashMap 为例说明一下,仅仅只是说明如何找到入门类,首先HashMap是符合这几点条件的,满足内容如下:
继承序列化,它有时候确实有要传输的需要
参数类型宽泛(这个也没有办法,为键值对,它就是需要类型不确定)
键值对,参数的类型不固定
重写readObject Hashmap为了保障它键值的唯一性,要计算键值的hash值,但是在不同的JVM中计算得出的Hash值可能是不同的,Hash值不同导致的结果就是:有可能一个HashMap对象的反序列化结果与序列化之前的结果不一致。
HashMap序列化的时候不会将保存数据的数组序列化,而是将元素个数以及每个元素的Key和Value都进行序列化。
在反序列化的时候,重新计算Key和Value的位置,重新填充一个数组。
HashMap 确实继承了Serializable这个接口。
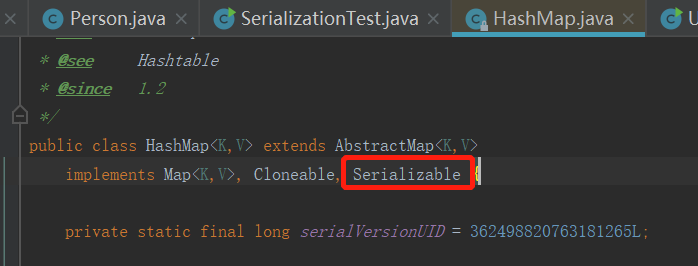
并且,HashMap确实重写了readObject方法,并且将Key 与 Value 的值执行了readObject的操作,再将 Key 和 Value 两个变量扔进hash这个方法里
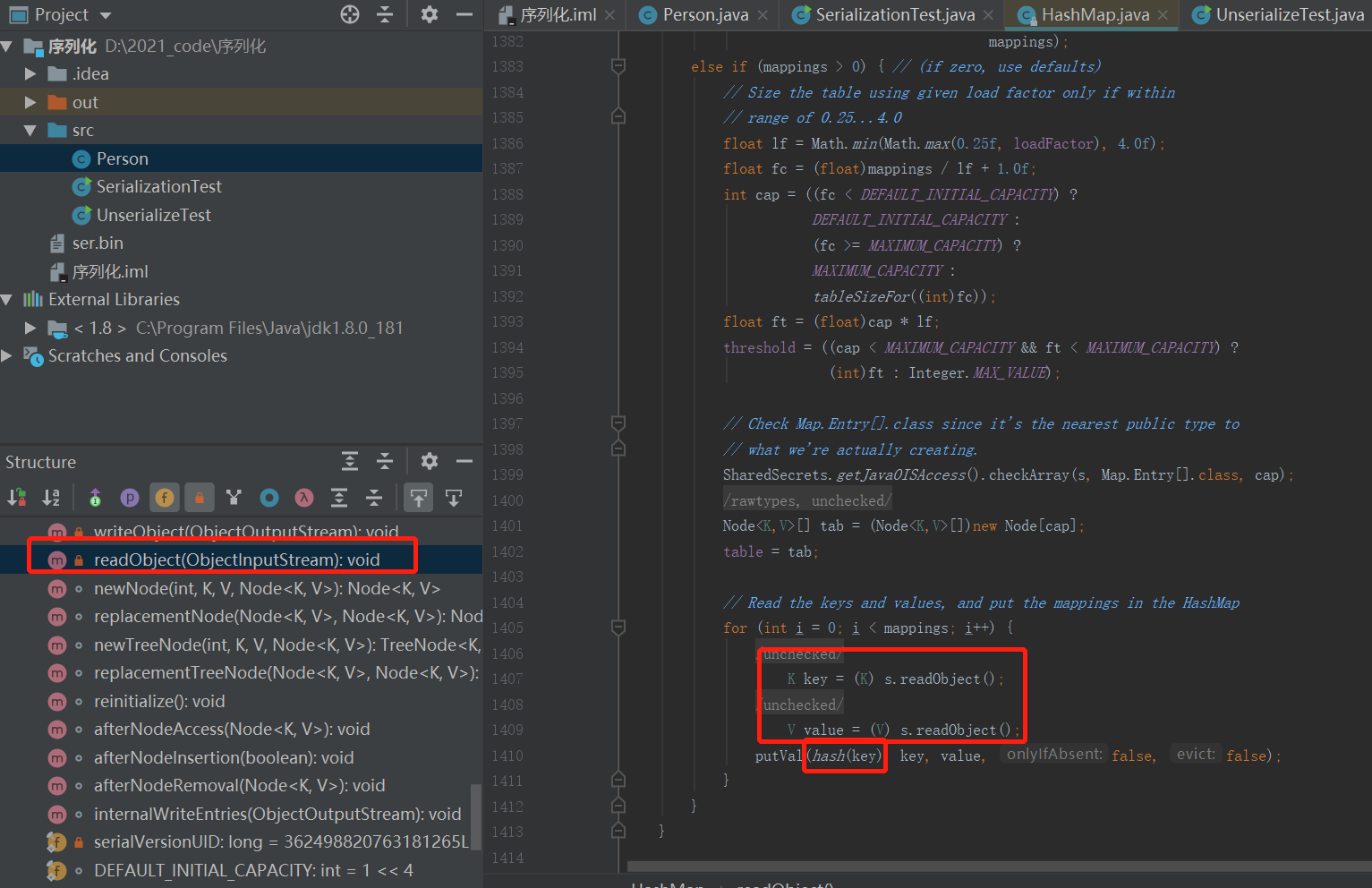
若传入的参数 key 不为空,则h = key.hashCode(),于是乎,继续跟进hashCode当中。
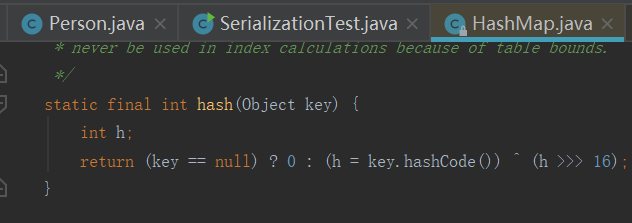
hashCode 位置处于 Object 类当中,满足我们调用常见的函数这一条件,所以说HashMap是个相当不错的入口类。
小结
本章总结了Java序列化及反序列化的内容,并从代码上进行一个简单地实现。归纳本文也是不断持续的巩固基础,常读常新。下一章会从代码中分析URLDNS利用链,并根据利用链编写一个对应的poc,以及会稍微复习一下Java中的反射。